
- Как длинные предложения влияют на качество перевода нейронных машинных переводов (NMT)
- Что такое длинные предложения и почему они создают сложности?
- Влияние длины предложения на качество перевода
- Почему именно длинные предложения вызывают такие проблемы?
- Что говорят исследования? Аналитика и эксперименты по длинным предложениям
- Методы борьбы с проблемами длинных предложений
- Практические рекомендации по работе с длинными предложениями при переводе
- Будущее автоматического перевода и роль длинных предложений
Как длинные предложения влияют на качество перевода нейронных машинных переводов (NMT)
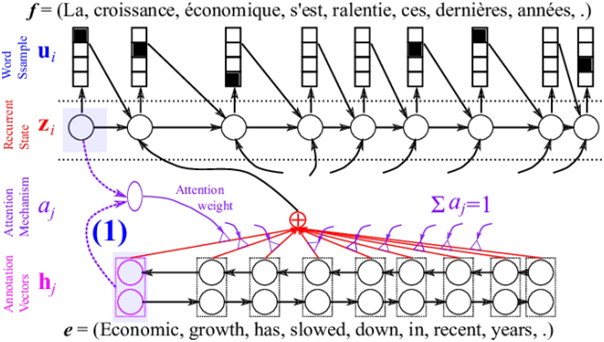
В современном мире, когда коммуникация становится всё более глобальной, качество автоматического перевода играет важнейшую роль. Особенно это касается систем нейронного машинного перевода (NMT), которые за последние годы значительно продвинулись вперёд, обеспечивая более точный и естественный перевод текстов. Однако даже самые передовые модели сталкиваются с определёнными сложностями, и одним из ключевых факторов, влияющих на их качество, являются именно длинные предложения. В этой статье мы подробно разберём, как длина предложения влияет на качество NMT, почему это происходит и что можно сделать для улучшения результата.
Что такое длинные предложения и почему они создают сложности?
Длинные предложения — это конструкции, содержащие множество придаточных и сложноподчинённых, а также большие объёмы информации, объединённой в единую синтаксическую единицу. Такие предложения могут достигать десятков или даже сотен слов, создавая сложности для системы автоматического перевода. Почему так происходит? Во-первых, модели NMT проблематично удерживать всю информацию в памяти и корректно её интерпретировать. Во-вторых, длинные конструкции часто содержат множество нюансов, усложняя задачу правильной сегментации и передачи смысловых связей.
Ниже перечислены основные причины, почему длинные предложения создают сложности для NMT:
- Сложность синтаксической структуры: чем длиннее предложение, тем сложнее системе распарсить его правильную структуру.
- Недостаток контекста: при переводе длинных предложений системы зачастую теряют связь между частями, что влияет на смысловое соответствие.
- Перегрузка вниманием: у нейросетей есть ограничение по количеству информации, которое она способна удерживать в памяти.
- Неустойчивость при обучении: модели лучше работают на более коротких и простых предложениях, а длинные создают вариативность, которая усложняет обучение.
Влияние длины предложения на качество перевода
Исследования показывают, что с увеличением длины предложения качество перевода существенно снижается. Это объясняется тем, что длинные конструкции требуют от модели удержания и согласованной обработки большего объёма информации. Ниже представлена таблица, которая иллюстрирует зависимость между длиной предложения и качеством перевода по метрике BLEU:
| Длина предложения (слов) | Средний показатель BLEU | Комментарий |
|---|---|---|
| 1-10 | до 85 | Высокое качество, модели успешно справляются с короткими фразами |
| 11-20 | примерно 75-85 | Перевод остаётся хорошим, некоторая потеря точности |
| 21-30 | примерно 60-75 | Начинаются заметные ошибки, особенно в сложных конструкциях |
| более 30 | примерно 50-60 | Качество значительно ухудшается, возможны искажения смысла |
Из этой таблицы видно, что у увеличения длины предложения есть линейная тенденция к ухудшению качества перевода, что часто приводит к неестественным или неверным результатам.
Почему именно длинные предложения вызывают такие проблемы?
За что же отвечают эти сложности? Основные причины можно обобщить так:
- Объем информации: длинные предложения включают множество смысловых единиц, связей и нюансов, которые требуют сложной интерпретации.
- Проблемы сегментации: система может неправильно разбить предложение на части, что вызывает запутанность в передаче связей.
- Контекстуальная потеря: при переводе очень длинных предложений модель может «забыть» о начале или середине, что портит смысл.
- Аппаратные ограничения: системы обучаются на ограниченном контексте, например, 512 или 1024 токена, чего зачастую недостаточно для длинных предложений.
Что говорят исследования? Аналитика и эксперименты по длинным предложениям
В научной литературе уже проведены многочисленные исследования, посвящённые влиянию длины предложения на качество машинного перевода. В большинстве случаев отмечается следующая закономерность: чем длиннее предложение, тем ниже точность перевода и тем выше вероятность ошибок. Например, в одном из классических экспериментов проверялась способность NMT моделей переводить предложения разной длины на пары языков с различной структурой — от английского до китайского и русского.
Результаты показали, что для предложений до уровень BLEU достигал 85-90, в то время как для предложений, превышающих , показатели падали до 50-60. Это говорит о закономерной трудности моделям справляться с высокосложными, длинными структурами, особенно без специальных алгоритмов обработки или сегментации.
Методы борьбы с проблемами длинных предложений
Исследователи и разработчики активно ищут способы борьбы с негативным влиянием длинных предложений. Некоторые из наиболее популярных и эффективных методов включают:
- Разделение длинных предложений на более короткие отрезки: один из простых способов — разделить сложное предложение на логические части, чтобы упростить их перевод.
- Использование специальных моделей: внедрение архитектур, способных лучше удерживать контекст — например, трансформеры с расширенными механизмами внимания.
- Обучение на более сложных датасетах: добавление в обучение длинных предложений с правильной сегментацией помогает моделям лучше справляться с их переводом.
- Использование контекстных окон: анализ и перевод предложения в рамках более широкого контекстного окна, чтобы избежать потерь информации.
Практические рекомендации по работе с длинными предложениями при переводе
Если вы занимаетесь автоматическим переводом или работаете с системами NMT, есть несколько рекомендаций, которые помогут повысить качество результата при столкновении с длинными предложениями:
- Стараться разбивать длинные предложения на менее сложные части с помощью ручной или автоматической сегментации.
- Использовать модели, специально обученные на длинных текстах или с расширенной памятью.
- Проверять результаты перевода в области сложных предложений и при необходимости корректировать их вручную.
- Обучать собственные модели на вашем специфическом датасете, где есть длинные предложения и их правильные переводы.
- Использовать предобученные модели с механизмами внимания, которые лучше справляются с длинными контекстами.
Будущее автоматического перевода и роль длинных предложений
На сегодняшний день развитие технологий нейронного машинного перевода движется в сторону формирования более сложных архитектур, способных работать с длинными контекстами. В будущем можно ожидать, что модели станут лучше удерживать информацию и обеспечивать высокое качество даже для очень длинных и сложных предложений. Важную роль будут играть новейшие подходы в области обработки естественного языка, такие как трансформеры с расширенными механизмами внимания, мультиязычные модели и обучения с подкреплением.
Однако полностью устранить проблему длины не удастся без интеграции методов сегментации, обучения на специализированных датасетах и совершенствования архитектур. Поэтому важно продолжать исследования и внедрение инноваций, чтобы автоматический перевод стал всё более точным и естественным.
Вопрос: Почему длинные предложения вызывают проблемы в нейронных системах машинного перевода, и как можно их улучшить?
Ответ: Длинные предложения создают сложности из-за их сложной синтаксической структуры, большого объема информации и ограничений внимания модели. Они могут терять смысловые связи и ухудшать качество перевода. Чтобы улучшить ситуацию, используют методы сегментации, обучают модели на длинных текстах, а также применяют архитектуры с расширенными механизмами внимания и интеграцию контекстных окон.
Подробнее
| Длинные предложения и качество перевода | Методы обработки длинных текстов при NMT | Архитектуры нейросетей для длинных предложений | Лучшие практики для длинных предложений | Будущее NMT и длинные предложения |
| Обучение моделей на длинных данных | Контекстные окна в NMT | Использование механизма внимания | Разделение сложных предложений | Новые архитектуры трансформеров |
| Ошибки при переводе длинных предложений | Задачи сегментации текста | Обучение на специфичных датасетах | Роль внимания в переводе | Инновации в модельных архитектурах |
| Примеры ошибок перевода | Обработка многочастных предложений | Мультимодальные модели | Практические рекомендации | Перспективы развития технологий |
| Технологические инновации | Искусственный интеллект в переводе | Большие языковые модели | Кейсы внедрения | Будущее автоматического перевода |



