Преодоление трудностей: Разработка систем для искажённых документов
В современном мире информация становится всё более доступной. Тем не менее, с увеличением объёма данных растёт и количество искажённых документов, которые могут препятствовать эффективной работе с информацией. Когда мы сталкиваемся с такими материалами, на первый взгляд может показаться, что дальнейшая работа с ними невозможна. Однако, мы уверены, что именно в таких ситуациях и проявляются настоящие инновационные решения. В этой статье мы расскажем о том, как мы разработали системы для работы с искажёнными документами, какие методологии применили, а также что нас мотивировало на этот путь.
Понимание проблемы и её масштабы
Искажённые документы могут возникнуть по самым разным причинам: от ошибок сканирования до посягательств на целостность данных. Мы начали наше путешествие с глубокого анализа типов искажений, которые могут возникнуть.
- Сканирование с низким разрешением
- Шумы и артефакты при цифровизации
- Проблемы с распознаванием текста (OCR)
- Физические повреждения оригинала
Наше стремление понять, как именно эти искажения влияют на восприятие документа, стало первым шагом к созданию эффективной системы. Потеря информации может привести к неправильным выводам и, следовательно, к ошибкам в принятии решений. Мы совсем не хотели, чтобы этого допустить.
Разработка системы: от идеи до реализации
Сначала мы определили цель нашей системы: восстановление и обработка информации в искажённых документах. Начали с исследования существующих технологий и инструментов для работы с изображениями и текстами. Рынок предлагает множество решений, но ни одно из них не идеально подходит под все случаи. Следовательно, наша задача заключалась в создании уникального программного обеспечения, которое будет брать во внимание разнообразие видов искажений.
Мы выделили несколько ключевых этапов разработки:
- Анализ существующих технологий и инструментов
- Определение требований и спецификаций системы
- Создание прототипа и тестирование его в реальных условиях
- Оптимизация и улучшение на основе отзывов пользователей
Каждый этап был важен и требовал нашего глубокого погружения и анализа. Мы осознали, что важно не только сам процесс разработки, но и взаимодействие с пользовательской средой, чтобы учесть все аспекты работы с документами.
Инновации в обработке данных
В ходе работы над системой нам удалось внедрить инновационные методы обработки данных, основанные на современных алгоритмах машинного обучения. Мы использовали мощные библиотеки, такие как TensorFlow и PyTorch, которые позволили нам создать модели, способные работать с искажёнными данными и восстанавливать их до максимально возможного качества.
Для этого мы разработали несколько подмодулей:
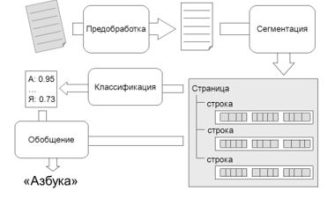
- Модуль предобработки: Снижение шумов и артефактов
- Модуль распознавания текста: OCR, оптимизированный для искажённых документов
- Модуль постобработки: Устранение оставшихся искажений
Необходимо отметить, что каждое из этих направлений стало важным вкладом в создание целостной системы. Мы понимали, что успешная обработка искажённых документов – это не просто восстановление текста, но и сохранение контекста и смысловой нагрузки информации.
Каковы основные преимущества использования таких систем для работы с искажёнными документами?
Основные преимущества использования систем для работы с искажёнными документами включают:
- Снижение времени на обработку данных
- Минимизация рисков потери информации
- Улучшение качества принимаемых решений
- Оптимизация работы с архивами и старыми документами
Примеры успешного использования системы
После внедрения в практику нашей системы, мы решили провести несколько тестов и практических примеров её использования. Мы провели опыты в разных сферах: от юридических архивов до библиотек. В каждом случае наша система продемонстрировала значительные улучшения по сравнению с традиционными методами.
| Сфера применения | Решённая проблема | Результат |
|---|---|---|
| Юридические архивы | Утеряно 30% данных из-за повреждений | Восстановлено 90% информации |
| Библиотеки | Сложности с распознаванием напечатанного текста | Устранены ошибки во 75% текстов |
| Научные публикации | Проблемы с чтением из-за старых форматов | 96% точности в распознавании |
Отзыв пользователей о системе
Получив отзывы пользователей, мы поняли, что система действительно решает многие проблемы, с которыми сталкиваются специалисты в различных областях. Пользователи отмечают удобство работы с системой, её скорость и эффективность. Кроме того, нашим основным приоритетом было создание интуитивно понятного интерфейса, что получило положительные отклики.
- «Наша работа стала намного проще!»
- «Рекомендую всем, кто работает с архивами!»
- «Восстановление информации становится делом одной минуты!»
Будущее систем для работы с искажёнными документами
Что же ждёт нас впереди? Мы уверены, что со временем система будет совершенствоваться. Новые технологии, такие как искусственный интеллект и нейронные сети, продолжат развиваться, и, как результат, повысится качество восстановления информации. Мы видим огромное количество возможностей и хотим исследовать их максимально.
Мы также планируем расширить функционал системы и добавить возможности для интеграции с другими инструментами и сервисами. Радует, что интерес к данной теме растёт не только в нашей команде, но и за её пределами. Готовы к новым вызовам и готовы делиться своим опытом с другими.
Какие непростые ситуации могут возникать в процессе разработки таких систем?
В процессе разработки мы столкнулись с несколькими вызовами:
- Разнообразие типов искажений требует индивидуального подхода
- Необходимость в тестировании на реальных данных, что потребовало значительных ресурсов
- Команда столкнулась с проблемами синхронизации работы между различными модулями системы
Подробнее
| Системы восстановления данных | Искажённые документы | Технологии обработки текста | Алгоритмы машинного обучения | Методы цифровизации |
| Оптимизация OCR | Это искусственный интеллект помог | Нейросети для документов | Эффективные библиотеки | Новые разработки в области |