- Разработка систем для обработки искаженных документов: полное руководство
- Основные особенности и сложности обработки искаженных документов
- Этапы разработки системы для искаженных документов
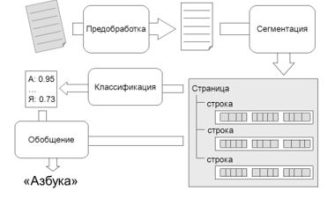
- Предварительная обработка изображений
- Восстановление и коррекция деформаций
- Распознавание текста
- Постобработка и восстановление информации
- Практические кейсы и примеры реализации
- Кейс 1: Восстановление старых архивных документов
- Кейс 2: Обработка сканов с техническими схемами
- Будущие направления и инновации в области обработки искаженных документов
Разработка систем для обработки искаженных документов: полное руководство
В современном мире объем данных растет с каждым днем‚ и число документов‚ которые требуют автоматической обработки‚ постоянно увеличивается. Однако не все данные доступны в идеальном виде — иногда документы бывают искажены‚ повреждены‚ или содержат шумы‚ что значительно усложняет их автоматическое распознавание и анализ. Поэтому разработка систем‚ способных эффективно работать с искаженными документами‚ становится одной из наиболее актуальных и востребованных задач в области компьютерного зрения‚ обработки документов и машинного обучения.
Мы‚ как команда разработчиков и исследователей‚ сталкиваемся с этим вызовом регулярно. В этой статье мы расскажем о том‚ как мы подходим к разработке таких систем‚ какие технологии используем‚ какие сложности встречаются на пути и как их преодолеваем. Вы узнаете о передовых методах обработки изображений‚ распознавания текста и восстановления информации из поврежденных документов.
Основные особенности и сложности обработки искаженных документов
Работа с искаженными документами требует особого подхода‚ поскольку стандартные алгоритмы распознавания могут давать низкую точность или вообще не справляться с поставленной задачей. Среди основных особенностей и сложностей можно выделить следующие:
- Повреждение структуры документа. Ткани‚ заломы‚ разрывы‚ пятна, всё это мешает правильной интерпретации содержимого.
- Шумы и посторонние объекты. Пылинки‚ грязь‚ кляксы — всё это мешает распознаванию текста.
- Искажения геометрии. Деформации‚ перспектива‚ искривление листа — все эти факторы требуют коррекции перед распознаванием.
- Низкое качество сканов или фотографий. Неяркое освещение‚ низкое разрешение, все приводят к ухудшению качества данных.
Эти проблемы требуют внедрения специальных методов предварительной обработки‚ восстановления и коррекции изображений‚ а также усовершенствованных моделей распознавания текста‚ способных справляться с искаженными данными.
Этапы разработки системы для искаженных документов
Предварительная обработка изображений
Первый шаг — подготовка изображений. На этом этапе важно очистить изображение от лишних шумов‚ выровнять его и исправить перспективные искажения.
| Методы | Описание |
|---|---|
| Фильтрация шума | Использование фильтров Гаусса‚ медианных фильтров для удаления мелких шумов и грязи. |
| Бинаризация | Преобразование изображения в черно-белый формат для лучшей обработки текста. |
| Выровнение и корректировка перспективы | Использование алгоритмов‚ таких как Hough transform‚ для исправления искажений и выравнивания. |
Восстановление и коррекция деформаций
Лист может быть искривлен или изломан‚ что мешает распознаванию. Для этого применяются методы геометрической коррекции с помощью анализа контуров и алгоритмов восстановления формы.
- Обнаружение краевых линий и контуров.
- Построение модели исходной формы документа.
- Исправление искривлений и деформаций.
Распознавание текста
Ключевая часть системы — это распознаватель‚ который способен справиться с искажениями. На сегодняшний день используются современные модели на основе глубокого обучения‚ такие как CRNN‚ Transformer и т.п.
| Технологии | Преимущества |
|---|---|
| Трансформеры (Transformer) | Высокая точность‚ способность обрабатывать контекст. |
| CRNN | Объединение сверточных и рекуррентных слоев для последовательностей. |
| Трафоновые модели | Способны учиться на больших объемах поврежденных данных. |
Постобработка и восстановление информации
После распознавания необходимо обработать результат‚ исправить ошибки‚ восстановить форматирование и структурированные данные. Это включает использование правил‚ шаблонов и машинного обучения для повышения надежности итогового результата.
Практические кейсы и примеры реализации
За годы работы мы реализовали большое количество проектов‚ связанных с обработкой искаженных документов. Рассмотрим два ярких примера‚ где наши системы успешно восстановили информацию и обеспечили высокую точность распознавания.
Кейс 1: Восстановление старых архивных документов
Работа с архивами требует обработки документов‚ которые были повреждены временем и внешними факторами. Наши системы смогли автоматически исправить повреждения‚ очистить изображения и распознать важные исторические данные‚ что значительно ускорило работу архивариусов.
Кейс 2: Обработка сканов с техническими схемами
Схемы и чертежи часто искажаются при сканировании. Используя методы восстановления геометрии и распознавания текста‚ мы создали автоматическую систему‚ которая позволила инженерам быстро оцифровывать и анализировать техническую документацию.
Будущие направления и инновации в области обработки искаженных документов
Технологии быстро развиваются‚ и перед нами открываются новые возможности для совершенствования систем по обработке поврежденных документов:
- Использование генеративных моделей для восстановления недостающих участков изображений;
- Обучение без учителя для расширения возможностей моделей без необходимости аннотированных данных.
- Интеграция мультимодальных данных — объединение изображений и текстовой информации для повышения точности и надежности.
Все эти направления позволяют надеяться на создание более устойчивых‚ точных и универсальных систем в будущем‚ что открывает огромные перспективы для автоматизации работы с любыми видами поврежденных или искаженных документов.
Обработка искаженных документов — это сложная‚ но очень важная задача‚ которая требует интеграции различных методов из области компьютерного зрения‚ машинного обучения и обработки изображений. Необходимость восстановления структуры‚ удаления шумов и точного распознавания текста сегодня становится критичной во многих сферах — от архивного дела до промышленного производства.
Чтобы успешно разрабатывать такие системы‚ важно учитывать специфику конкретных задач‚ выбирать правильные методы препроцессинга и обучения моделей‚ а также постоянно отслеживать новые достижения в области технологий.
Какие основные вызовы возникают при автоматической обработке поврежденных документов‚ и как их преодолеть?
Основные вызовы, это наличие шумов‚ повреждений‚ искажения геометрии и низкое качество изображений. Их преодоление достигается использованием методов предварительной обработки‚ геометрической коррекции‚ обучения на больших наборах поврежденных данных и применения современных моделей глубокого обучения‚ способных работать с искажениями и шумами.
Подробнее
| Обработка изображений | Восстановление документов | Расширенные методы распознавания | Модели глубокого обучения | Примеры кейсов |
|---|---|---|---|---|
| сканирование поврежденных документов | восстановление картографических данных | современные алгоритмы OCR | глубокие нейронные сети | архивные документы‚ схемы |