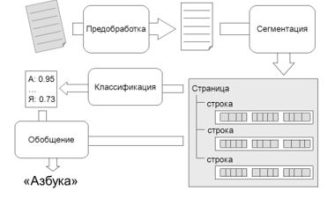
- Разработка систем для обработки искаженных документов: наши первые шаги в мире непредсказуемого текста
- Погружение в проблему: почему важно уметь работать с искажёнными документами
- Основные типы искажений в документах: виды и сложности обработки
- Какие основные искажения встречаются в практической работе?
- Проблемы‚ связанные с различными типами искажений
- Подходы и методы разработки систем для работы с искажёнными документами
- Обработка изображений и предобработка данных
- Использование методов компьютерного зрения и машинного обучения
- Интеграция методов OCR (оптическое распознавание символов)
- Практические примеры и кейсы
- Обработка архивных рукописных документов
- Обработка отсканированных документов с шумами и размытиями
- Перспективы развития и вызовы
Разработка систем для обработки искаженных документов: наши первые шаги в мире непредсказуемого текста
Погружение в проблему: почему важно уметь работать с искажёнными документами
В современном мире цифровых технологий мы всё чаще сталкиваемся с необходимостью автоматической обработки документов различного типа, будь то сканы старых архивных материалов‚ ресайзенные изображения текстов или даже файлы‚ поврежденные при передаче. Особенно остро эта проблема стоит при работе с «примятими»‚ «загрязненными» или полностью искажёнными документами‚ которые требуют особых методов распознавания и восстановления.
Компании в области юриспруденции‚ медицины‚ образования и бизнеса ежедневно сталкиваются с задачами автоматизации обработки огромных объёмов документов. Особенно важно успешно справляться с изображениями‚ содержащими шумы‚ деформации‚ размытости или даже частичные повреждения. В связи с этим‚ разработка эффективных систем для работы с такими файлами становится не просто актуальной‚ а жизненно необходимой для повышения скорости и точности работы.
Вопрос: Почему системы для работы с искажёнными документами имеют особое значение и какие задачи они должны решать?
Ответ: Такие системы помогают автоматически распознавать и восстанавливать текст‚ повышая эффективность обработки данных‚ сокращая человеческий фактор и минимизируя ошибки. Они должны уметь справляться с шумами‚ деформациями‚ частичной потерей информации и другими искажениямими‚ обеспечивая максимально точное восстановление исходного содержимого.
Основные типы искажений в документах: виды и сложности обработки
Какие основные искажения встречаются в практической работе?
Работа с искажёнными документами предполагает сталкиваться с разными типами повреждений и деформаций. Ниже приведены самые распространённые:
- Шумы и пятна: случайные точки‚ линии или пятна‚ появляющиеся в результате повреждений на сканах или фотографиях.
- Размытие и смазывание: размытие текста вследствие плохого качества сканирования или движения камеры.
- Деформации и изгибы: искривление линий текста при съемке с камеры под неправильным углом или в неприспособленных условиях.
- Частичная потеря данных: повреждение части текста‚ которая становится недоступной для распознавания.
- Искажения цвета и контрастности: невысокий контраст‚ размытые цвета‚ что затрудняет выделение текста на фоне изображения.
Проблемы‚ связанные с различными типами искажений
Каждый тип повреждения предъявляет свои требования к методам обработки. Например‚ шумы требуют фильтрации и устранения нестабильных элементов‚ тогда как деформации требуют геометрической коррекции. В практике зачастую приходится комбинировать разные методы для достижения оптимальных результатов‚ что делает задачу особенно сложной и интересной.
Подходы и методы разработки систем для работы с искажёнными документами
Обработка изображений и предобработка данных
Первый и очень важный этап в решении задачи — это подготовка исходных данных. Используемые методы позволяют значительно повысить качество распознавания‚ снизить влияние шумов и деформаций:
- Фильтрация шума: применяется для удаления случайных пикселей и пятен‚ делая изображение более четким.
- Улучшение контраста: помогает выделить текст на фоне‚ особенно при плохой освещенности или низком качестве снимка.
- Геометрическая коррекция: исправление искажений‚ скосов и изгибов путем применения аффинных или проектных преобразований.
Использование методов компьютерного зрения и машинного обучения
Для повышения точности обработки применяют современные подходы‚ использующие глубокое обучение и нейронные сети. Среди наиболее эффективных методов — использование сверточных нейронных сетей (CNN)‚ которые обучаются распознавать и исправлять различные виды искажений на изображениях документов.
| Метод | Описание | Плюсы | Минусы |
|---|---|---|---|
| Фильтрация изображений | Удаление шумов с помощью медианных‚ гауссовых фильтров | Простота реализации‚ быстрое выполнение | Может ухудшить детали текста при сильных шумах |
| Глубокое обучение | Обучение нейронных сетей для восстановления искаженного текста | Высокая точность‚ возможности автоматической коррекции | Требует большого объема размеченных данных и ресурсов |
Интеграция методов OCR (оптическое распознавание символов)
После подготовки изображения следует этап распознавания текста. Современные OCR-системы‚ такие как Tesseract‚ позволяют вывести содержимое изображения в текстовую форму. Однако‚ при работе с искажёнными документами обычные OCR-решения часто дают ошибочные результаты‚ поэтому требуется их доработка:
- Обучение OCR-моделей на искаженных данных: создание специальных наборов обучающих образцов‚ учитывающих различные деформации.
- Дополнительная постобработка текста: применение языковых моделей для исправления ошибок и повышения читаемости результатов.
Практические примеры и кейсы
Обработка архивных рукописных документов
Работа с историческими архивами, одна из наиболее сложных задач. Старые рукописи часто страдают от искажений‚ размазывания чернил и повреждений бумаги. В подобных случаях необходимо использовать сочетание методов:
- Генерация обучающих данных с имитацией повреждений и искажений.
- Применение нейронных сетей для восстановления текстов.
- Использование OCR с последующей редакцией для уточнения результата.
Обработка отсканированных документов с шумами и размытиями
Современные сканеры и мобильные устройства не всегда могут обеспечить идеально чистое изображение. В результате фото или сканы содержат шумы и размытие‚ что затрудняет автоматическое чтение. В таких случаях помогают алгоритмы фильтрации и геометрической коррекции‚ после которых применяются модели глубокого обучения для распознавания и исправления ошибок.
Перспективы развития и вызовы
Будущее систем для работы с искажёнными документами связано с развитием технологий искусственного интеллекта и компьютерного зрения. Среди главных вызовов, увеличение точности распознавания при минимальных затратах времени‚ обработка документов с необычными или великими искажениямими‚ а также автоматизация всего процесса в реальном времени.
Новые методы самообучения и использованием генеративных моделей позволяют создавать более устойчивые системы‚ способные к адаптации под новые виды повреждений без необходимости полного переобучения; Однако‚ для этого требуется большой объем тренировочных данных и вычислительных ресурсов.
Обработка и восстановление искажённых документов, это не просто технический вызов‚ а необходимость современного мира информации. Разрабатывая системы‚ способные эффективно решать эти задачи‚ мы повышаем качество работы различных отраслей‚ ускоряем обмен данными‚ делаем возможными новые формы взаимодействия и повышаем уровень защиты информации.
Нам стоит смотреть в будущее с оптимизмом — технологии продолжают развиваться‚ и уже сегодня практически каждую проблему можно превратить в вызов‚ который можно успешно решить при помощи новых алгоритмов‚ методов и подходов.
Вопрос: Какие основные технологии и методы помогают работать с искажёнными документами сегодня?
Ответ: Сегодня основными инструментами являются предобработка изображений (фильтрация‚ коррекция)‚ методы глубокого обучения (нейронные сети для восстановления текста)‚ OCR-технологии‚ а также языковые модели для постобработки результатов. Комбинация этих подходов позволяет достигать высокой точности и эффективности в работе с поврежденными документами.
Подробнее
| Обработка изображений для текстов | Машинное обучение для восстановления документов | OCR системы для поврежденных документов | Глубокое обучение в обработке текстов | Геометрическая коррекция изображений |
| Предобработка изображений документов | Автоматические системы исправления искажений | Обучение нейронных сетей для OCR | Особенности работы с рукописными текстами | Новые методы повышения точности распознавания |
| Обработка архивных документов | Роль языковых моделей в восстановлении | Образцы для обучения OCR | Инновационные алгоритмы для искажений | Перспективы автоматической обработки |
| Влияние деформаций на распознавание текста | Достижения в области искусственного интеллекта | Преимущества нейросетей в обработке документов | Технические барьеры и пути их преодоления | Будущее технологий восстановления текста |
| Автоматизация работы с поврежденными документами | Роль языковых моделей в постобработке | Создание датасетов для обучения | Инновационные темы исследования | Практическое применение систем восстановления |