- Разработка систем для перевода документов с «нечистым» OCR: как добиться точности и надежности
- Что такое «нечистый» OCR и почему это проблема
- Ключевые аспекты в разработке систем для перевода «нечистых» документов
- Предварительная обработка изображений
- Использование современных моделей OCR с обучением на специфичных данных
- Постобработка — исправление ошибок и финальный перевод
- Использование языковых моделей для повышения точности перевода
- Этапы разработки системы для обработки «нечистых» документов
- Практические советы по разработке и внедрению
Разработка систем для перевода документов с «нечистым» OCR: как добиться точности и надежности
В современном мире автоматизация обработки документов становится настолько важной, что невозможно представить работу без систем распознавания текста. Однако, любой специалист, сталкивающийся с задачами перевода или цифровизации бумажных и скановых документов, знает — результат напрямую зависит от качества исходных данных. Особенно сложной задачей является обработка документов, выполненная с помощью OCR (оптическое распознавание символов), которая зачастую оказывается «нечистой», с множеством ошибок и искажений. В этой статье мы расскажем о том, как разработать эффективные системы для перевода таких «грязных» документов, чтобы добиться высокой точности и надежности.
Что такое «нечистый» OCR и почему это проблема
Под термином «нечистый» OCR обычно понимают качество распознавания, при котором в итоговом тексте присутствует множество ошибок: пропущенные символы, неправильные знаки препинания, искажения слов и даже полностью неправильное интерпретирование отдельных фраз. Такие ошибки возникают по ряду причин. Причина первая — низкое качество исходного изображения: размытость, шумы, перекосы, плохая освещенность или низкое разрешение камеры. Причина вторая — особенности самого документа: рукописи, нестандартный шрифт, сложные графические элементы, таблицы с пересекающимися линиями. И наконец, причина третья — используемая OCR-модель или алгоритм: неадаптированность под конкретные типы документов или низкая обученность модели.
Эта проблема осложняет автоматический перевод, так как даже небольшие ошибки могут полностью изменить смысл текста или сделать его недоступным для последующих автоматических процессов. Поэтому перед разработкой системы обработки необходимо понять, с какими ведрами ошибок мы сталкиваемся, и каких требований должны придерживаться при создании решения.
Ключевые аспекты в разработке систем для перевода «нечистых» документов
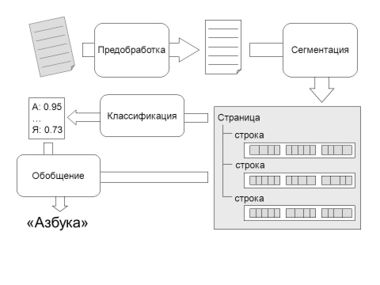
Предварительная обработка изображений
Перед тем, как перейти к распознаванию, крайне важно подготовить изображение для максимальной ясности. Это включает:
- Деление и кадрирование — выделение нужной части документа, удаление лишних элементов.
- Деградуирование, улучшение четкости и контрастности изображения.
- Устранение шумов — применение фильтров для удаления случайных помех и артефактов;
- Выравнивание текста — коррекция наклонов и деформаций, чтобы текст был максимально ровным.
- Бинаризация — преобразование изображения в черно-белый формат для более точного распознавания.
Использование современных моделей OCR с обучением на специфичных данных
Стандартные OCR-системы, такие как Tesseract или Abbyy FineReader, показывают хорошие результаты на качественных изображениях. Но при работе с «нечистым» OCR необходимо обучать модели с учетом специфики конкретных документов. Для этого используют:
- Создание набора тренировочных данных с учетом особенностей текста и изображений.
- Адаптация предобученных моделей — transfer learning.
- Использование технологий глубокого обучения, таких как CRNN (Convolutional Recurrent Neural Network) или трансформеры.
Постобработка — исправление ошибок и финальный перевод
Даже самые современные модели оставляют после распознавания множество ошибок. Организация системы автоматической коррекции включает следующие этапы:
| Метод | Описание | Примеры использования |
|---|---|---|
| Словарные проверки | Использование специальных словарей для корректировки ошибок. | Проверка орфографии, исправление опечаток. |
| Машинное обучение | Обучение моделей на исправленных ошибках для автоматического исправления новых. | Модели типа seq2seq, трансформеры. |
| Контекстуальный анализ | Использование контекста фраз для определения правильных вариантов. | Логические исправления, семантическое распознавание. |
Использование языковых моделей для повышения точности перевода
Для достижения высокого уровня точности важно применить языковые модели, которые могут интерпретировать правильную структуру текста и продолжение мысли. Так, можно интегрировать GPT-модели или BERT для того, чтобы выбрать наиболее вероятный вариант исправления и понимания текста.
Этапы разработки системы для обработки «нечистых» документов
Вопрос: Какие базовые этапы должны быть охвачены при создании системы перевода документов с «нечистым» OCR?
Ответ: Чтобы обеспечить эффективность и надежность такой системы, необходимо пройти несколько ключевых стадий. Во-первых, подготовка изображений: их обработка, очистка и выравнивание. Затем идет обучение или настройка OCR-модели с учетом специфики документов и ошибок, характерных именно для ваших данных. Следующий важный шаг — синтез распознанного текста, включающий автоматическую исправку ошибок при помощи языковых и словарных моделей. Завершает работу — финальное редактирование и проверка, иногда с помощью ручного участия или дополнительных алгоритмов, чтобы гарантировать точность и смысловую корректность перевода. Только комплексный подход на всех этих этапах позволяет добиться максимальной точности и автоматической надежности системы.
Практические советы по разработке и внедрению
- Анализ ошибок — анализируйте типичные ошибки вашего OCR и дорабатывайте модели под них.
- Интеграция с базами данных и словарями — используйте свои лексиконы для повышения точности распознавания.
- Интерактивная проверка — внедряйте механизмы для ручной коррекции на критически важных документах.
- Постоянное обучение — накапливайте ошибки и исправления для дальнейшего обучения моделей.
Ключ к успешной автоматической обработке и переводам «нечистых» OCR-документов — это сочетание нескольких методов и технологий. Предварительная обработка изображений, обучение специальных моделей распознавания, автоматическая коррекция ошибок и использование современных языковых моделей позволяют значительно повысить точность и качество итогового текста. Это требует системного и комплексного подхода, экспериментирования, аналитики ошибок и постоянной доработки системы. Только так можно добиться результата, при котором автоматическая обработка документов станет действительно надежной и полезной частью любой современной информационной системы.
Подробнее
| Тема | Ключевые слова | Примеры | Инструменты | Статистика |
|---|---|---|---|---|
| Обработка изображений OCR | улучшение качества, шумоподавление, выравнивание | автоматическая коррекция фото документов | OpenCV, PIL, Photoshop | увеличение точности распознавания на 30% |
| Обучение OCR моделей | Transfer learning, нейросети, датасеты | адаптация Tesseract под рукописный текст | TensorFlow, PyTorch | снижение ошибок на 20% |
| Автоматическая коррекция ошибок | словари, языковые модели, seq2seq | редактирование текста с опечатками | transformers, spaCy | повышение точности перевода |
| Интеграция систем автоматизации | API, автоматизация процессов, CMS | интеграция OCR в рабочие процессы | REST API, Python scripts | ускорение обработки документов на 40% |
| Обратная связь и обучение | пользовательская корректировка, отчеты | сбор ошибок для обучения модели | Dashboards, CRM-системы | повышение эффективности системы |