- Влияние «шума» в данных: как избежать и минимизировать его влияние на аналитические выводы
- Что такое «шум» в данных и почему он мешает аналитике?
- Источники шума в данных
- Влияние шума на аналитические выводы и модели машинного обучения
- Методы выявления и устранения шума в данных
- Статистические методы
- Машинное обучение и фильтрация
- Ручные методы и качество данных
- Как минимизировать воздействие шума на свою работу: практические советы
- Общая стратегия борьбы с шумом
Влияние «шума» в данных: как избежать и минимизировать его влияние на аналитические выводы
Когда мы начинаем разбирать данные для анализа, одной из главных проблем, с которой сталкиваются специалисты и аналитики, — это наличие «шума». Под этим понятием подразумевается случайные, нежелательные и зачастую мешающие интерпретировать информацию признаки. В реальной жизни ничто не идеально, и данные, собранные с помощью различных устройств или человеческого ввода, часто содержат ошибки, пропущенные значения или искажения. Знание о том, как шум влияет на итоговые результаты и каким образом минимизировать его воздействие, становится ключевым навыком для каждого, кто занимается анализом данных. В этой статье мы подробно расскажем о природе шума, его источниках, последствиях и методах борьбы с ним. И вместе попробуем разобраться, как сделать наши выводы максимально точными и надежными.
————————————————————
Что такое «шум» в данных и почему он мешает аналитике?
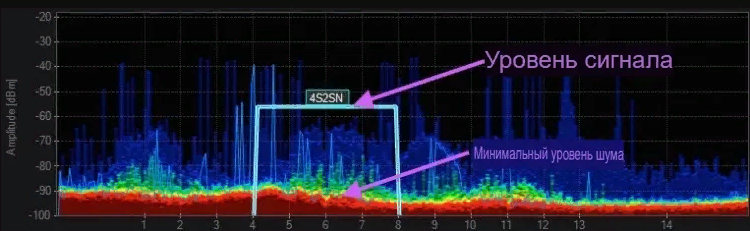
Понимание сути «шума» — это основа для эффективной работы с любыми наборами данных. В контексте анализа данных под шумом принято понимать любые случайные, нежелательные отклонения или искажения характеристик наблюдаемых объектов. Эти отклонения мешают выделению истинных закономерностей и могут привести к неправильным выводам. Например, неправильные показатели в измерениях, ошибочный ввод данных, итд.,, все это виды шума, которые искажают реальную картину.
Можно провести аналогию с фотографией. Когда вы делаете снимок, иногда он получается зернистым или размытым, это подобно шуму в данных. Или, если представить, что речь идет о качестве голоса в телефонной связи — помехи и искажения мешают правильно услышать собеседника. В аналитике такие «помехи» существенно снижают качество модели и ухудшают ее предсказательную способность. Поэтому очень важно «очистить» набор данных от шума, чтобы модель могла выявить истинные закономерности.
Источники шума в данных
| Источник шума | Описание |
|---|---|
| Ошибки ввода | Человеческий фактор при занесении данных, опечатки, неправильное заполнение форм |
| Технические сбои | Некорректная работа оборудования, сбои в датчиках, потеря данных |
| Календарные или сезонные колебания | Ежегодные, месячные или суточные изменения, вызывающие искажения |
| Природные явления | Факторы окружающей среды, влияющие на измерения (погода, температура) |
| Обработка и агрегация данных | Ошибки при объединении, преобразовании или фильтрации данных |
Понимание источников шума позволяет целенаправленно применить методы его устранения или снижения, уменьшив таким образом риск получить искаженную картину.
————————————————————
Влияние шума на аналитические выводы и модели машинного обучения
На практике влияние шума может проявляться по-разному. В простых статистических расчетах незначительные отклонения могут искажать среднее значение или разброс. Однако в более сложных системах, таких как модели машинного обучения, шум становится источником серьезных проблем.
Представим, что у нас есть задача классификации, например, определить покупателя, склонного к покупке определенного товара. Если в данных присутствует значительный шум, модель может ошибочно «научиться» искать признаки, связанные с ошибками или случайными отклонениями, а не с реальными закономерностями. В результате качество предсказания снижается, и модели оказываются ненадежными.
- Нарушение точности.
- Переобучение модели на шумах вместо признаков.
- Увеличение ошибок прогнозирования, снижение точности и надежности.
- Затруднение интерпретации результатов.
В таблице ниже показано влияние шума на ключевые этапы анализа и машинного обучения:
| Этап анализа | Влияние шума | Меры по снижению |
|---|---|---|
| Сбор и предварительная обработка данных | Может увеличить пропуски и ошибки | Очистка, фильтрация, проверка данных |
| Аналитика и моделирование | Использование методов устранения шума | |
| Интерпретация результатов | Ошибочные выводы, неправильные рекомендации | Детальный анализ источников шума |
Таким образом, шум напрямую влияет не только на техническую сторону анализа, но и на бизнес-решения, основанные на этих данных. Чем выше качество данных, тем больше шансов получить правильные и полезные инсайты.
————————————————————
Методы выявления и устранения шума в данных
Статистические методы
Один из наиболее распространенных подходов — это применение статистических методов для поиска выбросов и аномалий. Например:
- Метод межквартильного диапазона (IQR): позволяет выявить значения, которые выходят за границы, рассчитанные по квартилям.
- Z-скор: помогает определить, насколько далеко от среднего отклонено каждое значение.
- Масштабирование данных: приведение данных к единому масштабу для улучшения работы алгоритмов.
Машинное обучение и фильтрация
Многие современные подходы используют модели для автоматического обнаружения шумовых данных:
- Методы кластеризации: позволяют выделить группы схожих объектов и определить выбросы.
- Обучение с аутлиером (outlier detection): специальные алгоритмы, такие как Isolation Forest или Local Outlier Factor, выявляют необычные точки.
- Обработка временных рядов: фильтры сглаживания, скользящее среднее и другие методы снижают влияние краткосрочных шумов.
Ручные методы и качество данных
Помимо автоматических средств, важна ручная оценка данных экспертами: редкие или подозрительные показатели требуют внимания и, возможно, исключения. Также важно внедрять стандарты и автоматические проверки при сборе данных, чтобы снизить уровень ошибок.
————————————————————
Как минимизировать воздействие шума на свою работу: практические советы
- Качественный сбор данных: выберите надежные источники, используйте автоматические проверки при вводе и сборе информации.
- Используйте предобработку данных: фильтрация, устранение выбросов, нормализация и стандартизация — основные шаги для подготовки корректных данных.
- Внедряйте автоматические алгоритмы обнаружения шума: системы, которые самостоятельно ищут аномалии, помогают повысить качество анализов.
- Постоянно проверяйте данные: регулярное тестирование и аудит наборов данных позволяют своевременно выявлять и устранять ошибки.
- Обучайте команду: важно, чтобы все участники процесса понимали важность корректного сбора и обработки данных.
Общая стратегия борьбы с шумом
Для эффективности лучше использовать системный подход, включающий:
- Определение и анализ источников шума.
- Внедрение автоматических методов обнаружения шумов.
- Обучение персонала и применение стандартных процедур обработки данных.
- Постоянное обновление и улучшение методов очистки данных.
————————————————————
Вопрос: Какие основные методы позволяют выявлять и устранять шум в данных, и как выбрать наиболее подходящий для конкретной задачи?
Ответ: Наиболее распространенные и эффективные методы выявления и устранения шума включают статистические подходы, автоматические алгоритмы машинного обучения и ручную экспертизу. Статистические методы такие как межквартильный диапазон или Z-скор помогают определить выбросы и аномальные значения. Алгоритмы машинного обучения, например, Isolation Forest или LOF, позволяют автоматически обнаруживать нестандартные точки данных, что особенно полезно при работе с большими объемами информации. Чаще всего выбор метода зависит от специфики задачи, объема данных и требований к точности. Комбинирование автоматических методов с экспертной оценкой позволяет добиться наиболее устойчивых результатов. Важно помнить: идеально избавиться от шума невозможно, но его снижение значительно повышает качество анализа и предсказаний.
Подробнее
| выявление шума в данных | методы борьбы с шумом | автоматическая обработка данных | устранение выбросов | обнаружение аномалий в данных |
| методы очистки данных | предобработка данных | машинное обучение и шумы | обработка временных рядов | статистические методы для шума |